隨著大數據和復雜關系分析需求的增長,圖數據庫因其高效處理關聯數據的能力而備受關注。Nebula Graph 作為一款開源的分布式圖數據庫,以其高性能和可擴展性在業界廣受認可。本文將深入探討 Nebula Graph 的數據模型和系統架構設計,揭示其如何支撐復雜的圖數據應用。
一、Nebula Graph 的數據模型
Nebula Graph 采用屬性圖模型作為其核心數據模型,該模型直觀且靈活,適合表示實體及其之間的關系。其數據模型主要包括以下要素:
1. 點(Vertex):代表圖中的實體,如用戶、產品或地點。每個點具有唯一的標識符(VID)和一組屬性(例如,用戶的姓名、年齡)。
2. 邊(Edge):表示點之間的關系,如“關注”或“購買”。邊是有向的,并包含起始點、結束點、類型和屬性(例如,關系的權重或時間戳)。
3. 標簽(Tag):用于對點進行分類,每個點可以關聯多個標簽,每個標簽定義了一組屬性。例如,一個點可以同時有“用戶”和“VIP”標簽。
4. 邊類型(Edge Type):定義邊的語義,例如“朋友”或“交易”,允許在查詢時過濾特定關系。
這種模型支持復雜的圖遍歷和模式匹配,使得 Nebula Graph 在社交網絡、推薦系統和知識圖譜等場景中表現優異。數據以圖空間(Space)為單位進行組織,每個空間可獨立管理,便于多租戶部署。
二、Nebula Graph 的系統架構設計
Nebula Graph 采用分布式架構,確保高可用性、可擴展性和低延遲。其系統架構主要由三個核心組件構成:
1. 元服務(Meta Service):負責集群管理和元數據存儲,包括圖空間、標簽、邊類型和分片信息的定義。它通過 Raft 協議實現一致性,確保元數據的可靠性和快速恢復。
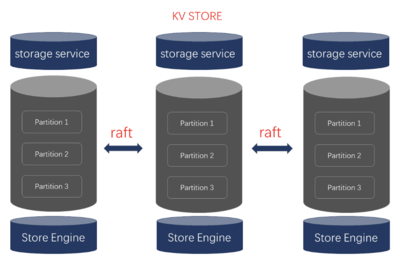
2. 存儲服務(Storage Service):處理圖數據的持久化存儲和查詢。數據被水平分片(Partition)分布到多個存儲節點上,每個分片通過多副本機制(基于 Raft)保證數據冗余和容錯。存儲引擎優化了圖遍歷操作,支持快速點邊查詢和屬性過濾。
3. 查詢引擎(Query Engine):負責解析和執行查詢語言(nGQL),將用戶請求轉換為分布式任務。它通過計算下推(Push-down)優化,減少網絡傳輸,并與存儲服務協同處理復雜圖算法,如最短路徑或社區發現。
Nebula Graph 還包括圖形化工具(如 Nebula Studio)和客戶端 SDK,提升開發體驗。整個架構支持線性擴展,用戶可通過添加節點輕松應對數據增長。
Nebula Graph 的數據模型通過屬性圖簡化了關系表示,而其分布式系統架構則確保了高性能和可靠性。這種設計使其成為處理大規模圖數據的理想選擇,適用于從實時分析到機器學習等多種應用場景。隨著圖數據庫技術的演進,Nebula Graph 將繼續推動數據智能的發展。